Der Mythos „Lose Kopplung“ Teil 2 - Jenseits des Mythos: Wie echte Modularität entsteht und wann Microservices wirklich sinnvoll sind.
Im ersten Teil haben wir uns mit der verbreiteten Annahme beschäftigt, dass lose Kopplung automatisch zu besseren Software-Architekturen führt. Wir haben gesehen, dass diese Sicht zwar eingängig klingt, aber nur einen kleinen Ausschnitt der Realität abbildet. Viel öfter steckt der eigentliche Kern des Problems nicht in der Architektur, sondern in der fehlenden strukturellen Disziplin innerhalb großer Codebasen. Genau hier knüpfen wir jetzt an und gehen der Frage nach, wie man die dringend benötigte Struktur tatsächlich herstellen kann – und ab welchem Punkt Microservices wirklich eine sinnvolle Option darstellen.
Modularisierung beginnt im Kleinen – und im Code
Eine schöne Architekturzeichnung ist schnell gemacht. Saubere fachliche Grenzen sind schnell in Kästchenform skizziert. Doch der eigentliche Test findet immer dort statt, wo es ernst wird: im Code. Und genau hier entsteht oft die Diskrepanz, die George Fairbanks so treffend als „The Code Gap“ bezeichnet hat. Die Architektur möchte Trennung, der Code erlaubt aber Durchgriffe an Stellen, an denen sie eigentlich nicht erlaubt wären.
Ein Grund liegt schlicht in den Programmiersprachen selbst. Viele bieten nur grobgranulare Sichtbarkeitsmechanismen. Das Konzept eines „Moduls“ als fachliche Einheit existiert häufig nicht oder nur sehr eingeschränkt. Dadurch lassen sich fachliche Grenzen zwar auf dem Papier definieren, im Code jedoch nur schwer erzwingen. Genau das führt zu schleichenden Verwässerungen: Abhängigkeiten entstehen, weil sie technisch möglich sind, nicht weil sie fachlich sinnvoll wären.
Frameworks wie Java Modules oder Spring Modulith liefern hier eine Art Kontrollinstanz, indem sie zwischen „public“ und „published“ unterscheiden und damit bestimmte Teile eines Moduls gezielt sicht- oder unsichtbar machen können. Auf diese Weise lassen sich architektonische Regeln nicht nur dokumentieren, sondern auch vom Compiler durchsetzen. Die Architektur wird so vom Vorschlag zur Garantie.
Form folgt Struktur – Module als Bausteine
Noch mehr Kontrolle erreicht man, wenn man das Deployment-Artefakt bewusst aus einzelnen Development-Artefakten zusammensetzt. Das heißt: Jedes Modul wird zu einem eigenem Artefakt, beispielsweise einem eigenen JAR oder Paket. Abhängigkeiten werden ausschließlich über das Build-System definiert. Dadurch entsteht eine unmissverständliche, technische Grenze.
Der Vorteilliegt auf der Hand: Ein Modul kann nur das nutzen, was sein Dependency-Graph zulässt. Und was nicht verbunden ist, kann auch nicht versehentlich gekoppelt werden. Zusätzlich können einzelne Artefakte ganz gezielt getestet werden – nicht im großen Verbund, sondern isoliert mit genau dem Teil des Systems, den sie laut Architektur kennen dürfen. Das sorgt für eine saubere Architektur und eine höhere Lebensdauer jeder fachlichen Trennung.
Mit diesem Ansatz steigt aber auch die Komplexität. Dependencies müssen verwaltet werden, und sobald mehrere Versionen eines Moduls parallel existieren, vervielfacht sich der Testaufwand. Das ist insbesondere in Multi-Mandanten-Szenarien relevant, in denen verschiedene Kundenversionen gleichzeitig gepflegt werden müssen. Trotz dieser Herausforderungen bleibt der strukturelle Gewinnbeachtlich: Über Artefakte lässt sich ein Monolith in logisch klar getrennte Blöcke zerlegen, ohne sofort ein verteiltes System ausrollen zu müssen.
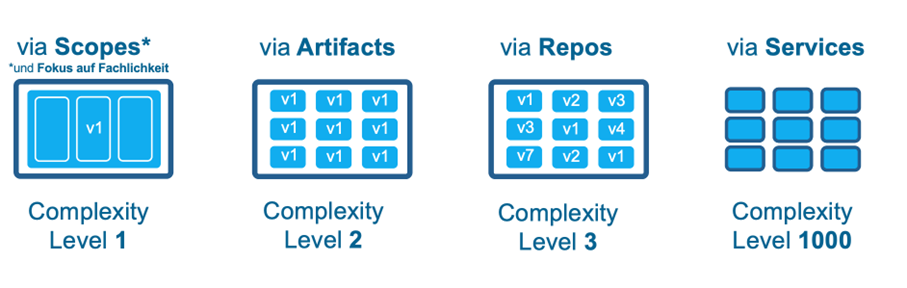
Abb. 1:Ansätze zur Strukturierung und Modularisierung
Wenn Struktur nicht reicht – das Deployment wird zur Grenze
Alle bisher beschriebenen Ansätze führen letztlich zu einem Deployment-Monolithen, der jedoch intern modular und kontrolliert aufgebaut ist – ein Modulith. Und für erstaunlich viele Systeme reicht genau dieser Zustand aus. Der Code ist sauber strukturiert, die Abhängigkeiten sind geklärt, die Module lassen sich isoliert testen, und dennoch bleibt die Einfachheit eines gemeinsamen Deployments erhalten.
Aber es bleibt eine entscheidende Grenze bestehen: Die Module sind nicht unabhängig deploy bar. Sie können nicht separat skaliert werden. Und sie müssen synchron ausgeliefert werden, weil sie sich denselben Lebenszyklus teilen.
An genau dieser Stelle kommt der Punkt ins Spiel, an dem Microservices mehr sind als nur ein Trend: Wenn ein System eine echte Unabhängigkeit zur Laufzeit benötigt.
Vielleicht, weil Teile des Systems unterschiedlich stark skaliert werden müssen. Vielleicht, weil einzelne Module besonders kritisch sind und unabhängig voneinander aktualisiert werden sollen. Vielleicht, weil organisatorische oderregulatorische Anforderungen klare Trennungen erzwingen. Diese Art der Unabhängigkeit lässt sich über Code-Organisation und Artefaktstrukturen allein nicht erreichen.
Erst wenn Module getrennt deployt werden können, entsteht die berühmte Laufzeit-Unabhängigkeit. Erst dann ist ein Modul wirklich für sich verantwortlich. Aber genau dann entstehen auch all die Komplexitäten, die wir in Teil 1 beleuchtet haben: APIs, Resilience, Infrastruktur, Versionierung, Orchestrierung.
Microservices als bewusste, nicht automatische Entscheidung
Wenn man all diese Faktoren zusammenführt, wird klar, dass Microservices kein logischer Endpunkt guter Architektur sind. Man entwickelt nicht automatisch von einem Modulith in Richtung eines verteilten Systems, nur weil die Struktur sauberer wird.
Die richtige Frage lautet nicht „Wie kommen wir schneller zu Microservices?“, sondern:
„Welche konkrete Art von Unabhängigkeit brauchen wir – und warum?“
Wenn die Unabhängigkeit sich primär auf die Entwicklung bezieht – also auf Wartbarkeit, Testbarkeit, Verständlichkeit –, dann reichen Modulith-Ansätze in der Regel aus. Die meisten Systeme profitieren enorm davon, ohne jemals den Schritt zu Microservices gehen zu müssen. Die zusätzlichen Komplexitäten einer verteilten Architektur stehen dann meist in keinem Verhältnis zum Nutzen.
Wenn jedoch die Unabhängigkeit zur Laufzeit im Vordergrund steht – also Skalierungsanforderungen, getrennte Deployments oder eine gezielte Isolation fachlicher Bereiche –, dann können Microservices sehr wohl sinnvoll sein. Aber eben nur dann.
Fazit: Architektur ist kein Dogma, sondern eine bewusste Abwägung
Der Mythos der losen Kopplung entsteht oft, wenn wir das Ziel aus den Augen verlieren und den Weg mit einer Wahrheit verwechseln. Lose Kopplung ist nicht falsch, aber sie ist nicht automatisch richtig. Und vor allem ist sie nicht immer der effizienteste Weg, um ein System wartbar, robust und zukunftsfähig zu gestalten.
Eine saubere Modularisierung – egal ob über Scopes, Artefakte oder Repositories – bringt bereits einen Großteil der gewünschten Unabhängigkeit. Sie sorgt für klare fachliche Grenzen, weniger Risiko von Seiteneffekten und eine deutlich höhere Wartbarkeit. Die meisten Systeme brauchen genau das, nicht mehr.
Microservices dagegen sind ein Werkzeug für spezielle Anforderungen, bei denen die Vorteile die unvermeidlichen Kosten übersteigen. Sie sind kein Ziel an sich, sondern eine bewusste Entscheidung für echte Laufzeit-Flexibilität – und nur dann ihre Komplexität wert.
Wir teilen unser Wissen gerne und hoffen dir hat unsere Blogreihe gefallen.
Unsere Experten stehen jederzeit zur Verfügung und beantworten alle Fragen zu ihren Blogartikeln.
Eine schöne Architekturzeichnung ist schnell gemacht. Saubere fachliche Grenzen sind schnell in Kästchenform skizziert. Doch der eigentliche Test findet immer dort statt, wo es ernst wird: im Code. Und genau hier entsteht oft die Diskrepanz, die George Fairbanks so treffend als „The Code Gap“ bezeichnet hat. Die Architektur möchte Trennung, der Code erlaubt aber Durchgriffe an Stellen, an denen sie eigentlich nicht erlaubt wären.
Ein Grund liegt schlicht in den Programmiersprachen selbst. Viele bieten nur grobgranulare Sichtbarkeitsmechanismen. Das Konzept eines „Moduls“ als fachliche Einheit existiert häufig nicht oder nur sehr eingeschränkt. Dadurch lassen sich fachliche Grenzen zwar auf dem Papier definieren, im Code jedoch nur schwer erzwingen. Genau das führt zu schleichenden Verwässerungen: Abhängigkeiten entstehen, weil sie technisch möglich sind, nicht weil sie fachlich sinnvoll wären.
Frameworks wie Java Modules oder Spring Modulith liefern hier eine Art Kontrollinstanz, indem sie zwischen „public“ und „published“ unterscheiden und damit bestimmte Teile eines Moduls gezielt sicht- oder unsichtbar machen können. Auf diese Weise lassen sich architektonische Regeln nicht nur dokumentieren, sondern auch vom Compiler durchsetzen. Die Architektur wird so vom Vorschlag zur Garantie.
Form folgt Struktur – Module als Bausteine
Noch mehr Kontrolle erreicht man, wenn man das Deployment-Artefakt bewusst aus einzelnen Development-Artefakten zusammensetzt. Das heißt: Jedes Modul wird zu einem eigenem Artefakt, beispielsweise einem eigenen JAR oder Paket. Abhängigkeiten werden ausschließlich über das Build-System definiert. Dadurch entsteht eine unmissverständliche, technische Grenze.
Der Vorteilliegt auf der Hand: Ein Modul kann nur das nutzen, was sein Dependency-Graph zulässt. Und was nicht verbunden ist, kann auch nicht versehentlich gekoppelt werden. Zusätzlich können einzelne Artefakte ganz gezielt getestet werden – nicht im großen Verbund, sondern isoliert mit genau dem Teil des Systems, den sie laut Architektur kennen dürfen. Das sorgt für eine saubere Architektur und eine höhere Lebensdauer jeder fachlichen Trennung.
Mit diesem Ansatz steigt aber auch die Komplexität. Dependencies müssen verwaltet werden, und sobald mehrere Versionen eines Moduls parallel existieren, vervielfacht sich der Testaufwand. Das ist insbesondere in Multi-Mandanten-Szenarien relevant, in denen verschiedene Kundenversionen gleichzeitig gepflegt werden müssen. Trotz dieser Herausforderungen bleibt der strukturelle Gewinnbeachtlich: Über Artefakte lässt sich ein Monolith in logisch klar getrennte Blöcke zerlegen, ohne sofort ein verteiltes System ausrollen zu müssen.
Abb. 1:Ansätze zur Strukturierung und Modularisierung
Wenn Struktur nicht reicht – das Deployment wird zur Grenze
Alle bisher beschriebenen Ansätze führen letztlich zu einem Deployment-Monolithen, der jedoch intern modular und kontrolliert aufgebaut ist – ein Modulith. Und für erstaunlich viele Systeme reicht genau dieser Zustand aus. Der Code ist sauber strukturiert, die Abhängigkeiten sind geklärt, die Module lassen sich isoliert testen, und dennoch bleibt die Einfachheit eines gemeinsamen Deployments erhalten.
Aber es bleibt eine entscheidende Grenze bestehen: Die Module sind nicht unabhängig deploy bar. Sie können nicht separat skaliert werden. Und sie müssen synchron ausgeliefert werden, weil sie sich denselben Lebenszyklus teilen.
An genau dieser Stelle kommt der Punkt ins Spiel, an dem Microservices mehr sind als nur ein Trend: Wenn ein System eine echte Unabhängigkeit zur Laufzeit benötigt.
Vielleicht, weil Teile des Systems unterschiedlich stark skaliert werden müssen. Vielleicht, weil einzelne Module besonders kritisch sind und unabhängig voneinander aktualisiert werden sollen. Vielleicht, weil organisatorische oderregulatorische Anforderungen klare Trennungen erzwingen. Diese Art der Unabhängigkeit lässt sich über Code-Organisation und Artefaktstrukturen allein nicht erreichen.
Erst wenn Module getrennt deployt werden können, entsteht die berühmte Laufzeit-Unabhängigkeit. Erst dann ist ein Modul wirklich für sich verantwortlich. Aber genau dann entstehen auch all die Komplexitäten, die wir in Teil 1 beleuchtet haben: APIs, Resilience, Infrastruktur, Versionierung, Orchestrierung.
Microservices als bewusste, nicht automatische Entscheidung
Wenn man all diese Faktoren zusammenführt, wird klar, dass Microservices kein logischer Endpunkt guter Architektur sind. Man entwickelt nicht automatisch von einem Modulith in Richtung eines verteilten Systems, nur weil die Struktur sauberer wird.
Die richtige Frage lautet nicht „Wie kommen wir schneller zu Microservices?“, sondern:
„Welche konkrete Art von Unabhängigkeit brauchen wir – und warum?“
Wenn die Unabhängigkeit sich primär auf die Entwicklung bezieht – also auf Wartbarkeit, Testbarkeit, Verständlichkeit –, dann reichen Modulith-Ansätze in der Regel aus. Die meisten Systeme profitieren enorm davon, ohne jemals den Schritt zu Microservices gehen zu müssen. Die zusätzlichen Komplexitäten einer verteilten Architektur stehen dann meist in keinem Verhältnis zum Nutzen.
Wenn jedoch die Unabhängigkeit zur Laufzeit im Vordergrund steht – also Skalierungsanforderungen, getrennte Deployments oder eine gezielte Isolation fachlicher Bereiche –, dann können Microservices sehr wohl sinnvoll sein. Aber eben nur dann.
Fazit: Architektur ist kein Dogma, sondern eine bewusste Abwägung
Der Mythos der losen Kopplung entsteht oft, wenn wir das Ziel aus den Augen verlieren und den Weg mit einer Wahrheit verwechseln. Lose Kopplung ist nicht falsch, aber sie ist nicht automatisch richtig. Und vor allem ist sie nicht immer der effizienteste Weg, um ein System wartbar, robust und zukunftsfähig zu gestalten.
Eine saubere Modularisierung – egal ob über Scopes, Artefakte oder Repositories – bringt bereits einen Großteil der gewünschten Unabhängigkeit. Sie sorgt für klare fachliche Grenzen, weniger Risiko von Seiteneffekten und eine deutlich höhere Wartbarkeit. Die meisten Systeme brauchen genau das, nicht mehr.
Microservices dagegen sind ein Werkzeug für spezielle Anforderungen, bei denen die Vorteile die unvermeidlichen Kosten übersteigen. Sie sind kein Ziel an sich, sondern eine bewusste Entscheidung für echte Laufzeit-Flexibilität – und nur dann ihre Komplexität wert.
Wir teilen unser Wissen gerne und hoffen dir hat unsere Blogreihe gefallen.
Unsere Experten stehen jederzeit zur Verfügung und beantworten alle Fragen zu ihren Blogartikeln.